File organization
This section describes how the necessary files (layout, data, images and font files) must be organized, where they are stored, what they must be called, and so on.
When the Publisher starts, it reads the current (working) directory and all child directories and saves the file names in a list. As soon as a resource is loaded, this list is used to check whether a corresponding file exists. No distinction is made as to which directory the file is located in.
It follows from this:
- If something changes in the file system during the run, the Publisher will not notice this.
- It does not matter what the directories are called. The images can, but do not have to be stored in the directory with the name "images".
- If the working directory is too large, the startup process is slow. A few thousand files in the working directory are usually no problem.
-
If there are duplicates in the file tree, a file is selected “at random”. E.g.
data.xmlin the main directory and in a subdirectory.
There are exceptions to the rule:
-
You can use
sp --no-localto instruct the publisher not to search the working directory recursively. -
With
--extra-diryou can add a directory to be searched recursively. -
With
sp --systemfonts, font files are also searched in directories that are predefined by the system. -
With
sp --wd DIRthe publisher changes to this directory before starting.
For a description of the parameters see the appendix Running the speedata publisher on the command line.
What names must the data file and the layout file have?
The speedata Publisher looks for the layout with the name layout.xml and the data file with the name data.xml. Both can be adjusted on the command line (--layout=XYZ and --data=XYZ) and in the configuration file (layout=XYZ and data=XYZ). See the appendices Running the speedata publisher on the command line and How to configure the speedata publisher.
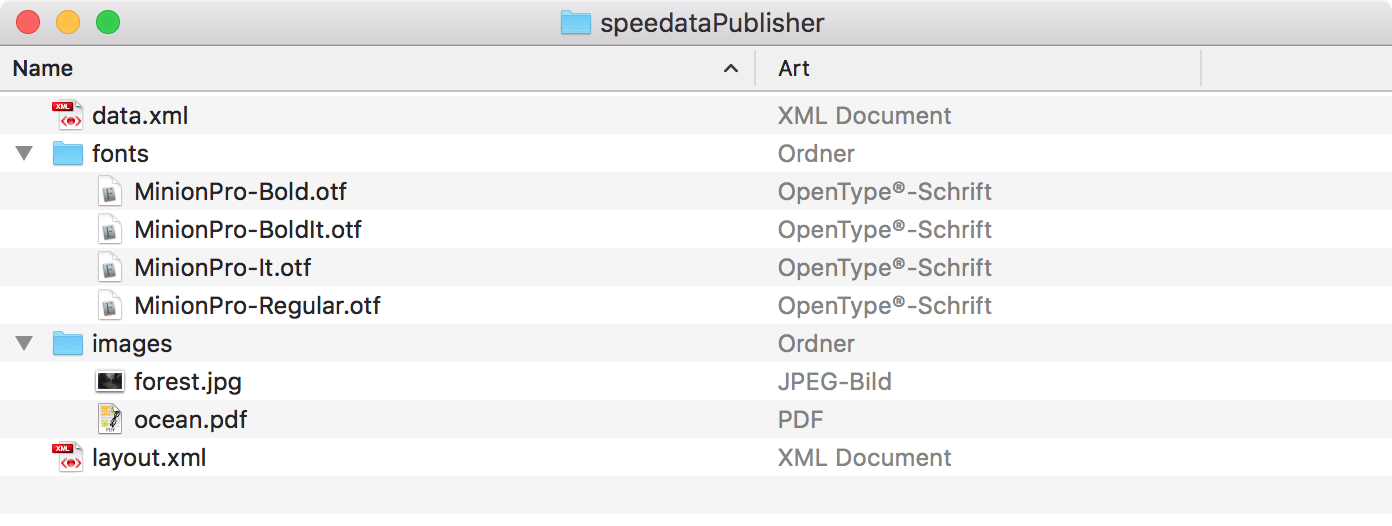
Possible file organization in a directory. The name of the subdirectories (folders) is arbitrary.
Splitting layout sets of rules into individual files
You can split the layout ruleset into several files. There are two ways to merge the files. On the command line, you can use --extra-xml to specify one or more layout rulesets, which are also read in. Alternatively, you can use the mechanism via XInclude, here in the case of a font definition:
<Layout
xmlns="urn:speedata.de:2009/publisher/en">
<LoadFontfile name="DejaVuSerif" filename="DejaVuSerif.ttf" />
...
</Layout>
This file can then be included with
<Layout xmlns="urn:speedata.de:2009/publisher/en"
xmlns:sd="urn:speedata:2009/publisher/functions/en"
xmlns:xi="http://www.w3.org/2001/XInclude"
>
<xi:include href="dejavu.xml"/>
...
</Layout>
The namespace for XInclude must be declared as above, otherwise there will be a syntax error in the XML file.
Grouping layout instructions with Section
The <Section> element allows you to group layout instructions without affecting the output.
This is useful for organizing large layout files, e.g. for code folding in text editors.
The element has a name attribute that serves as a label.
<Layout xmlns="urn:speedata.de:2009/publisher/en"
xmlns:sd="urn:speedata:2009/publisher/functions/en">
<Section name="Fonts and colors">
<LoadFontfile name="title" filename="title.otf" />
<DefineFontfamily name="title" fontsize="14"pt leading="16pt">
<Regular fontface="title"/>
</DefineFontfamily>
<DefineColor name="highlight" value="#cc0000" />
</Section>
<Section name="Page setup">
<Pageformat width="210mm" height="297mm" />
<SetGrid height="12pt" width="5mm" />
</Section>
<Record element="data">
...
</Record>
</Layout>
<Section> can also be used inside <Record> or other elements.
It can be freely combined with <xi:include>.
Splitting data into individual files
The data file can also be split into several files. XInclude is used for this.
<catalog xmlns:xi="http://www.w3.org/2001/XInclude">
<xi:include href="globalsettings.xml"/>
<xi:include href="article0001.xml"/>
<xi:include href="article0002.xml"/>
...
</catalog>
The namespace for XInclude must be declared in the root node (in the above example, 'catalog').
XInclude and XML schema
If the XInclude mechanism is used, it is possible that the XML editor will flag the <xi:include …> statements as unknown.
To prevent this, the RELAX NG schema must be linked to the editor instead of the XML schema. See the chapter Associate XML editor with schema.