Dateiorganisation
In diesem Abschnitt wird beschrieben, in welcher Art und Weise die notwendigen Dateien (Layout, Daten, Bilder und Schriftdateien) organisiert werden müssen, wo sie gespeichert werden, wie sie heißen müssen und so weiter.
Wenn der Publisher startet, wird das aktuelle (Arbeits-)Verzeichnis und alle Kindverzeichnisse eingelesen und die Dateinamen in einer Liste gespeichert. Sobald eine Ressource geladen wird, wird in dieser Liste nachgeschaut, ob eine entsprechende Datei existiert. Dabei wird nicht unterschieden, in welchem Verzeichnis die Datei liegt. Daraus folgt:
- Wenn sich während des Laufs etwas im Dateisystem ändert, bekommt der Publisher davon nichts mit.
- Es ist egal, wie die Verzeichnisse heißen. Die Bilder können, müssen aber nicht, im Verzeichnis mit dem Namen »bilder« gespeichert sein.
- Wenn das Arbeitsverzeichnis zu groß ist, ist der Startvorgang langsam. Einige Tausend Dateien im Arbeitsverzeichnis sind in der Regel kein Problem.
-
Gibt es Duplikate im Dateibaum, wird eine Datei »zufällig« ausgewählt. Z.B.
data.xmlim Hauptverzeichnis und in einem Unterverzeichnis.
Es gibt Ausnahmen von der Regel:
-
Man kann mit
sp --no-localden Publisher anweisen, das Arbeitsverzeichnis nicht rekursiv zu durchsuchen. -
Mit
--extra-dirkann man ein Verzeichnis hinzufügen, das rekursiv durchsucht wird. -
Mit
sp --systemfontswird für Schriftdateien auch in Verzeichnissen gesucht, die vom System vorgegeben sind. -
Mit
sp --wd DIRwechselt der Publisher vor dem Start in dieses Verzeichnis.
Für eine Beschreibung der Parameter siehe den Anhang Starten des Publishers über die Kommandozeile.
Welche Namen müssen die Daten- und die Layoutdatei haben?
Der speedata Publisher sucht das Layout mit dem Namen layout.xml und die Datendatei mit dem Namen data.xml.
Beide lassen sich auf der Kommandozeile (--layout=XYZ und --data=XYZ) und in der Konfigurationsdatei anpassen (layout=XYZ und data=XYZ).
Siehe dazu die Anhänge Starten des Publishers über Kommandozeile und Konfigurieren des Publishers.
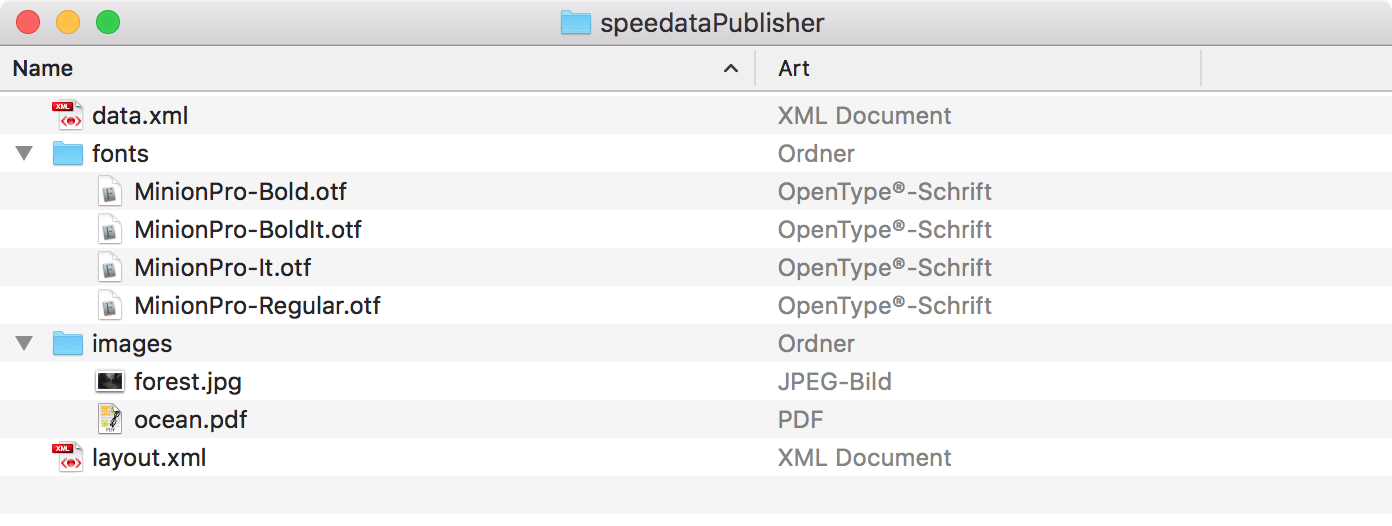
Mögliche Dateiorganisation in einem Verzeichnis. Der Name der Unterverzeichnisse (Ordner) ist beliebig.
Layoutregelwerke in einzelne Dateien teilen
Man kann das Layoutregelwerk in mehrere Dateien aufteilen.
Es gibt zwei Möglichkeiten, die Dateien zusammenzuführen.
Auf der Kommandozeile kann man mit --extra-xml ein oder mehrere Layoutregelwerke angeben, die zusätzlich eingelesen werden.
Alternativ dazu kann man den Mechanismus über XInclude benutzen, hier im Fall einer Fontdefinition:
<Layout
xmlns="urn:speedata.de:2009/publisher/en">
<LoadFontfile name="DejaVuSerif" filename="DejaVuSerif.ttf" />
...
</Layout>
Anschließend kann diese Datei eingebunden werden mit
<Layout xmlns="urn:speedata.de:2009/publisher/en"
xmlns:sd="urn:speedata:2009/publisher/functions/en"
xmlns:xi="http://www.w3.org/2001/XInclude"
>
<xi:include href="dejavu.xml"/>
...
</Layout>
Der Namensraum für XInclude muss wie oben deklariert werden, sonst gibt es einen Syntaxfehler in der XML-Datei.
Layoutanweisungen mit Section gruppieren
Mit dem Element <Section> können Layoutanweisungen gruppiert werden, ohne die Ausgabe zu beeinflussen.
Das ist nützlich, um große Layoutdateien übersichtlicher zu gestalten, z.B. für Code-Faltung (Code Folding) im Texteditor.
Das Element hat ein Attribut name, das als Beschriftung dient.
<Layout xmlns="urn:speedata.de:2009/publisher/en"
xmlns:sd="urn:speedata:2009/publisher/functions/en">
<Section name="Schriften und Farben">
<LoadFontfile name="titel" filename="titel.otf" />
<DefineFontfamily name="titel" fontsize="14pt" leading="16pt">
<Regular fontface="titel"/>
</DefineFontfamily>
<DefineColor name="hervorhebung" value="#cc0000" />
</Section>
<Section name="Seiteneinstellungen">
<Pageformat width="210mm" height="297mm" />
<SetGrid height="12pt" width="5mm" />
</Section>
<Record element="daten">
...
</Record>
</Layout>
<Section> kann auch innerhalb von <Record> oder anderen Elementen verwendet werden.
Es lässt sich beliebig mit <xi:include> kombinieren.
Daten in einzelne Dateien aufteilen
Auch die Datendatei kann in mehrere Dateien aufgeteilt werden. Hierzu wird XInclude genutzt.
<catalog xmlns:xi="http://www.w3.org/2001/XInclude">
<xi:include href="globalsettings.xml"/>
<xi:include href="article0001.xml"/>
<xi:include href="article0002.xml"/>
...
</catalog>
Im Wurzelknoten (im obigen Beispiel 'catalog') muss der Namensraum für XInclude deklariert werden.
XInclude und Schema
Wird der XInclude-Mechanismus benutzt, so kann es sein, dass der XML Editor die <xi:include …>-Anweisungen als unbekannt bemängelt.
Um das zu verhindern, muss das RELAX NG Schema anstelle des XML-Schemas mit dem Editor verknüpft werden. Siehe das Kapitel Schema zuweisen.