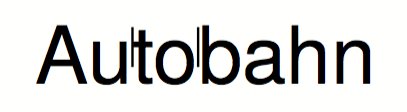
Silbentrennung / Spracheinstellungen
Silbentrennung ist in den meisten westlichen Sprachen notwendig, um ein akzeptables Erscheinungsbild für schmale Texte zu haben. Silbentrennung ist ein integraler Bestandteil des Umbruchalgorithmus, beispielsweise weil vermieden werden soll, dass mehrere Trennungen in aufeinanderfolgenden Zeilen auftreten.
Die Silbentrennung wird im Publisher über die Sprache gesteuert und musterbasiert vorgenommen.
Die Sprache kann man global einstellen über <Options mainlanguage="…"> oder Absatzweise.
<Options mainlanguage="German" />
stellt das gesamte Dokument auf deutsche Trennmuster um, während
<Paragraph language="German">
<Value>Autobahn</Value>
</Paragraph>
nur für einen Absatz die Sprache umstellt.
Die verfügbaren Sprachen sind in der Befehlsreferenz unter <Options> beschrieben.
Alternativ zu den ausgeschriebenen Namen wie German kann auch der Sprachcode verwendet werden.
Die beiden Beispiele oben können auch wie folgt benutzt werden:
<Options mainlanguage="de" />
<Paragraph language="de">
<Value>Autobahn</Value>
</Paragraph>
Möchte man testen, ob die Wörter richtig getrennt werden, kann man mit <Trace hyphenation="yes" /> kleine Markierungen erzeugen lassen.
<Layout
xmlns="urn:speedata.de:2009/publisher/en"
xmlns:sd="urn:speedata:2009/publisher/functions/en">
<Options mainlanguage="German" />
<Trace hyphenation="yes" />
<Record element="data">
<PlaceObject>
<Textblock width="3">
<Paragraph>
<Value>Autobahn</Value>
</Paragraph>
</Textblock>
</PlaceObject>
</Record>
</Layout>
ergibt folgendes:
Trennstellen anzeigen im Text
Mittels
<Hyphenation>er-go-no-mic</Hyphenation>
kann man für einzelne Wörter Trennvorschläge bzw. -ausnahmen definieren. So werden die Wörter dann nur an den mit Bindestrich angegebenen Stellen getrennt. Die Trennausnahme gilt für die Hauptsprache des Dokuments. Mit dem Attribut language kann man die Sprache festlegen, für die die Trennausnahme gilt.
| Mit optischem Randausgleich, der im Abschnitt Optischer Randausgleich beschrieben ist, kann man die Anzahl der Silbentrennungen im Dokument etwas verringern. |
Trennungen für Absätze ausschalten
Für einzelne Absätze kann man die automatische Silbentrennung ausschalten, in dem man ein Textformat definiert mit hyphenate="no"
<DefineTextformat name="nohyphen" hyphenate="no"/>
In so markierten Absätze werden keine Wörter getrennt. Die Anwendung von Textformaten ist in einem eigenen Abschnitt beschrieben.
Das Zeichen für die Silbentrennung kann man ebenfalls über ein Textformat verändern:
<DefineTextformat name="dothyphen" hyphenchar="•"/>

Anderes Zeichen für Worttrennungen
Verschiedene Sprachen innerhalb eines Absatzes benutzen
Man kann die Sprache für einen Textblock, einen Absatz und sogar für Teile eines Absatzes setzen. Dazu umgibt man den Text mit <Span language="…"> und </Span>.
<Paragraph language="en">
<Span language="de">
<Value>Also schön, Guido Heffels,
nachfolgend meine Textempfehlung
für das Blindtextbuch.
</Value>
</Span>
<Br />
<Span>
<Value>A wonderful serenity has taken
possession of my entire soul, like these sweet
mornings of spring which I enjoy with my whole
heart.
</Value>
</Span>
</Paragraph>
Trennungen nur an bestimmten Zeichen zulassen
Eine Eigenschaft von <Paragraph> erlaubt die Zeichen einzugrenzen, an denen ein Zeilenumbruch eingefügt werden darf.
Das ist bei technischen Daten oft wichtig, wo z. B. Typenbezeichnungen in der Form 12-345/AB vorkommen, und nicht getrennt werden sollen.
Im folgenden Beispiel darf nur hinter einem Schrägstrich umbrochen werden:
<Paragraph allowbreak="/">
<Value>https://download.speedata.de/publisher/development/</Value>
</Paragraph>
Die Voreinstellung für allowbreak ist " -", also ein Umbruch an einem Leerzeichen oder einem Trennstrich.
| Das ist ein experimentelles Feature im Publisher. Wahrscheinlich wird dies in einer zukünftigen Version einem Textformat zugeordnet werden. |
Spracheinstellungen für nicht-westliche Sprachen
Manche Sprachen haben besondere Satzregeln, die sich nicht auf die Silbentrennung auswirken, sondern auf das Erscheinungsbild des Textes. So können die Zeichen ihre Form oder Position verändern, je nach dem wo sie im Wort stehen. Um dieses Feature zu nutzen müssen folgende Bedingungen erfüllt sein:
-
mode="harfbuzz"muss bei<LoadFontfile>aktiviert sein. -
Die Sprache sollte korrekt eingestellt sein. Falls die Sprache nicht in der Liste der unterstützten Sprachen vorhanden ist, muss
Otheroder--(zwei Striche) eingestellt werden. Wenn die Sprache nicht korrekt eingestellt ist, kann es zu Darstellungsproblemen kommen. - Die gewählte Schriftart muss die entsprechenden Zeichen enthalten.
<Layout xmlns="urn:speedata.de:2009/publisher/en"
xmlns:sd="urn:speedata:2009/publisher/functions/en"
version="4.1.7">
<LoadFontfile name="NotoSansBengali-Regular"
filename="NotoSansBengali-Regular.ttf"
mode="harfbuzz" />
<DefineFontfamily fontsize="10" leading="12" name="text">
<Regular fontface="NotoSansBengali-Regular" />
</DefineFontfamily>
<Record element="data">
<PlaceObject>
<Textblock>
<Paragraph language="Other">
<Value>আমি</Value>
</Paragraph>
</Textblock>
</PlaceObject>
</Record>
</Layout>

Die Sprache wird vom System selbst erkannt, wenn sie auf
Other gesetzt ist.Rechts-nach-links laufender Text
Wird Text ausgegeben, der von rechts nach links läuft (z.B. Arabisch), muss die Richtung des Absatzes mit
angegeben werden (direction="rtl").
Ansonsten ist die Ausrichtung ggf. falsch (die letzte Zeile ist dann linksbündig anstelle von rechtsbündig).
Falls kein Blocksatz ausgegeben wird, muss im Textformat bei der Ausrichtung start und end benutzt werden und nicht leftaligned und rightaligned. start und end orientieren sich an der Startposition des Textes und nicht an der Orientierung der Seite (Ausgabefläche).
<Layout xmlns="urn:speedata.de:2009/publisher/en"
xmlns:sd="urn:speedata:2009/publisher/functions/en"
version="4.1.16">
<LoadFontfile
name="Amiri-Regular"
filename="amiri-regular.ttf"
mode="harfbuzz" />
<DefineFontfamily fontsize="10" leading="12" name="text">
<Regular fontface="Amiri-Regular" />
</DefineFontfamily>
<Record element="data">
<PlaceObject>
<Textblock width="5">
<Paragraph direction="rtl">
<Value select="."/>
</Paragraph>
</Textblock>
</PlaceObject>
</Record>
</Layout>
<data>المادة 1 يولد جميع الناس أحرارًا متساوين في الكرامة والحقوق.
وقد وهبوا عقلاً وضميرًا وعليهم أن يعامل بعضهم بعضًا بروح الإخاء.</data>

Der Text läuft von rechts nach links.
Gemischter Text (rechts-nach-links und links-nach-rechts)
Wird Text ausgegeben, der sowohl von rechts nach links (rtl, right to left) als auch von links nach recht (ltr) läuft, muss der Absatz in einzelne Segmente unterteilt werden und zwischen den Segmenten die Schreibrichtung geändert werden. Dieser sogenannte »Bidi-Algorithmus« ist im speedata Publisher eingebaut
und wird mit bidi="yes" aktiviert:
<PlaceObject>
<Textblock width="5">
<Paragraph bidi="yes">
<Value select="."/>
</Paragraph>
</Textblock>
</PlaceObject>
<data>العاشر ليونيكود (Unicode Conference)،
الذي سيعقد في 10-12 آذار 1997 مبدينة</data>
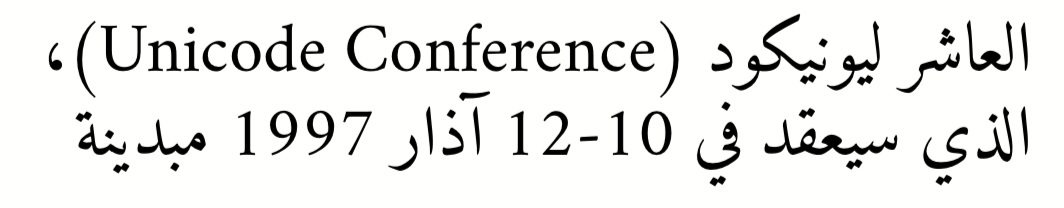
Hier wird die Textrichtung für jedes Teilstück separat berechnet. Wird
bidi="yes" angegeben, wird der erste Teil als Hauptrichtung des Absatzes genommen, in diesem Fall ist die Angabe direction="rtl" nicht notwendigRegeln für gemischten Text
-
Setze das Attribut
direction, wenn klar ist, in welchem Kontext der Text erscheinen soll. Wenn es leer oder nicht gesetzt ist, entscheidet der Inhalt des Textes, welche Richtung der Absatz haben soll. Das klappt in den meisten Fällen gut, aber beispielsweise nicht mit gemischtem Text, der mit einer »falschen« Richtung anfängt. -
Setze das Attribut
bidiim Zweifelsfall aufyes. Der einzige Nachteil ist, dass der Publishing-Lauf etwas langsamer sein könnte. Andere Unterschiede sollten nicht auftreten. -
Die Spracheinstellung (
language) sollte entweder die richtige Sprache beinhalten, leer sein oder auf die SpracheOthergesetzt werden. Das Problem ist, dass manche Spracheinstellungen eine unerwünschte Schreibrichtung erwirken können. -
Als Textausrichtung (
alignmentbei DefineTextformat) sollte anstelle vonleftoderrightlieberstartundendbenutzt werden.startundendorientieren sich an der Richtung für den Absatz. - Es muss der HarfBuzz-Fontlader aktiviert sein.